25 Vision I: From Photons to Retinal Codes
From photons to retinal codes
Touch tells an animal what has already reached the body. By the time pressure or heat is registered at the skin, the branch, the flame, or the ground is already in contact with it. Vision operates at the other end of the reactive–predictive gradient introduced in the unit overview. Light arrives from objects at a distance, and distance creates time: time to approach food, avoid a vehicle, intercept a moving target, or prepare for an approaching threat. A distance sense therefore extends the control loop beyond the body’s immediate boundary. It converts spatial separation into lead time for action.
The front of the eye is usefully compared with a camera. The cornea and lens focus light, the iris regulates the aperture, and an inverted image forms on a light-sensitive surface. The analogy becomes misleading at the retina. Photographic film or an electronic image sensor records a pattern of light. The retina is neural tissue that transforms that pattern. It adjusts its operating range to the recent illumination, separates light increments from decrements, compares each region with its neighbors, compares the outputs of different cone classes, and distributes the results among parallel populations of ganglion cells. The optic nerve does not carry a pixel-by-pixel copy of the retinal image. It carries the output of a layered neural circuit.
This is the first of three chapters on vision. The present chapter remains at the front end: the optics of the eye, the organization of the retina, phototransduction, ON and OFF pathways, center–surround organization, the beginnings of color coding, and the parallel outputs that form the optic nerve. The next chapter follows those axons through the optic chiasm, lateral geniculate nucleus, optic radiations, and primary visual cortex, where retinal signals are selectively recombined for orientation, binocular disparity, chromatic boundaries, motion, and form. The third turns to higher visual systems and asks how distributed representations support objects, faces, scenes, visually guided behavior, and conscious visual experience.
The difficult material in this chapter is easier to follow when it is treated as a sequence of transformations:
photons → photoreceptor voltage → glutamate release → ON and OFF pathways → spatial and spectral comparisons → ganglion-cell spikes
Each step changes what the signal means. The same photon that closes channels in a photoreceptor can ultimately increase firing in one ganglion cell and decrease it in another. Understanding vision begins by tracing those signs carefully rather than assigning a permanent meaning to “light,” “glutamate,” excitation, or inhibition.
25.1 An image forms on neural tissue
Light entering the eye first crosses the cornea, which supplies most of the eye’s focusing power. It then passes through the pupil, whose diameter is controlled by the iris, and through the lens, which changes shape during accommodation to refine focus for objects at different distances. The transparent vitreous fills most of the globe. At the back lies the retina, a thin sheet of neural tissue on which the optics form an image that is inverted from top to bottom and reversed from left to right.
The inversion is not a problem that requires the brain to turn a picture upright. Neural circuits learn and preserve relationships among retinal locations, body movements, and events in the world. The more consequential problem is that any two-dimensional retinal image is compatible with many possible three-dimensional arrangements. A small nearby object and a larger distant object can project the same retinal extent. That inverse problem becomes central when later visual systems infer depth, surfaces, and objects; it will be taken up in the third vision chapter. The retina begins the transformation of the image before those ambiguities are resolved.
The retina is not uniform. At the center of gaze lies the macula, within which the fovea contains the highest density of cones and supports the finest spatial vision. Nasal to the fovea, ganglion-cell axons gather at the optic disc and leave the eye as the optic nerve. Because photoreceptors are absent from the optic disc, it creates a blind spot in each eye. The spot is normally unnoticed because the two eyes cover partly overlapping regions and because visual experience is constructed from information across space and time rather than inspected as a literal retinal photograph.
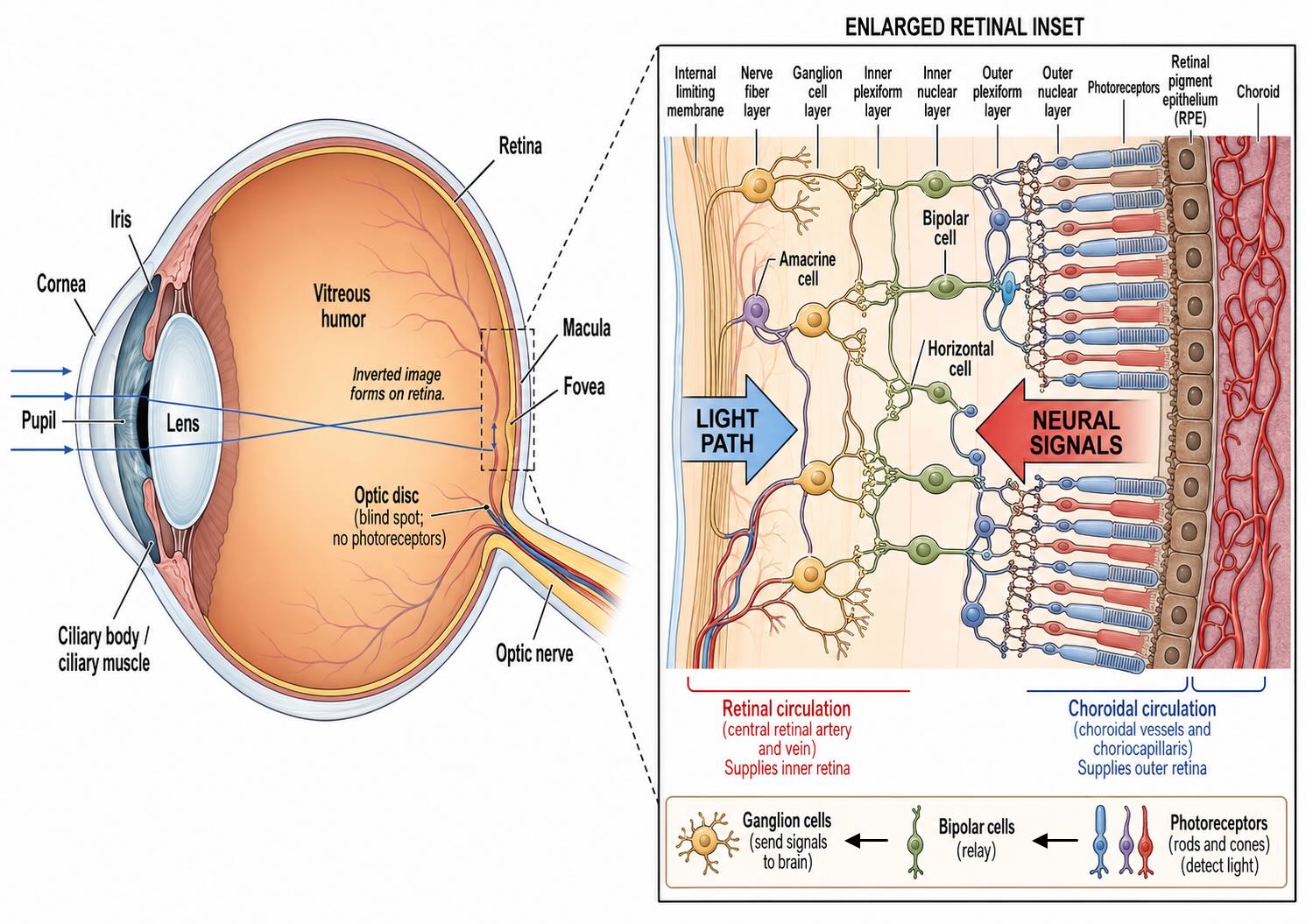
25.1.1 The inverted vertebrate retina
The vertebrate retina is often described as “backward.” Light enters from the ganglion-cell side and passes through the inner retinal layers before reaching the rods and cones. The photoreceptor outer segments point away from the incoming light and lie next to the retinal pigment epithelium, or RPE. Ganglion-cell axons must then run across the inner retinal surface and pass through the photoreceptor sheet at the optic disc.
This arrangement carries optical costs in terms of light sensitivity. The organization is inherited from the development of the vertebrate optic cup and cannot be evaluated apart from the structures that now support it. Photoreceptor outer segments (outer here meaning toward the sclera, away from the vitreous) must remain closely apposed to the RPE, which recycles the retinal chromophore used by opsins, regulates the extracellular environment, absorbs stray light, transports nutrients and waste, and ingests the tips of outer segments that photoreceptors continually renew. The metabolically demanding outer retina receives most of its oxygen from the dense choroidal circulation behind the RPE, whereas the inner retina is supplied principally by retinal vessels [@WangsaWirawanLinsenmeier2003; @JoyalEtAl2018].
The neural layers are also more transparent than a tangle of cells might suggest. Müller glia span the thickness of the retina and can guide light toward photoreceptors, reducing some of the scattering imposed by the inverted arrangement [@FranzeEtAl2007]. At the fovea, inner retinal neurons and vessels are displaced away from the optical axis, creating a pit and a central avascular region through which light reaches densely packed cones with relatively little obstruction. These specializations do not make the inverted arrangement optically free; they make it workable.
Cephalopods evolved camera eyes independently. Their photoreceptors face the incoming light and their output fibers leave from behind, so they do not create a vertebrate-style optic disc. The contrast is a reminder that evolution modifies inherited developmental arrangements rather than selecting from a clean sheet of possible designs.
25.1.2 Light sensitivity came before image-forming eyes
Opsin-based light sensitivity is much older than the vertebrate eye. In the unit overview, Chlamydomonas illustrated the minimal control loop: a light-sensitive eyespot biases flagellar movement, allowing a single cell to steer relative to illumination. No image is formed, but a physical variable has been transduced and coupled to action.
Image-forming eyes elaborate that basic relation in several ways. A flat photosensitive patch can report the presence of light. Pigment placed behind or beside the receptors creates directional shading. Recessing the patch into a cup improves directional sensitivity; narrowing the opening produces a pinhole image but reduces the amount of light admitted; adding a lens gathers more light while preserving spatial detail. These are not stages through which every eye lineage passed, nor rungs on a ladder leading toward the human eye. They are useful design possibilities, several of which remain represented in living animals [@NilssonPelger1994; @Nilsson2009; @LandNilsson2012].
The diversity of eyes follows the diversity of lives. Compound eyes favor wide fields and rapid temporal sampling. Nocturnal eyes favor photon capture. Raptors devote extraordinary resources to resolving distant detail. Many birds retain four cone classes and sensitivity into the ultraviolet. Camera eyes evolved independently in vertebrates and cephalopods. “Better vision” is therefore incomplete without a behavioral question: better for detecting what, under which illumination, and in time to perform which action? [@PorterEtAl2012; @HartHunt2007; @LindEtAl2014]
25.2 The retina is a layered neural circuit
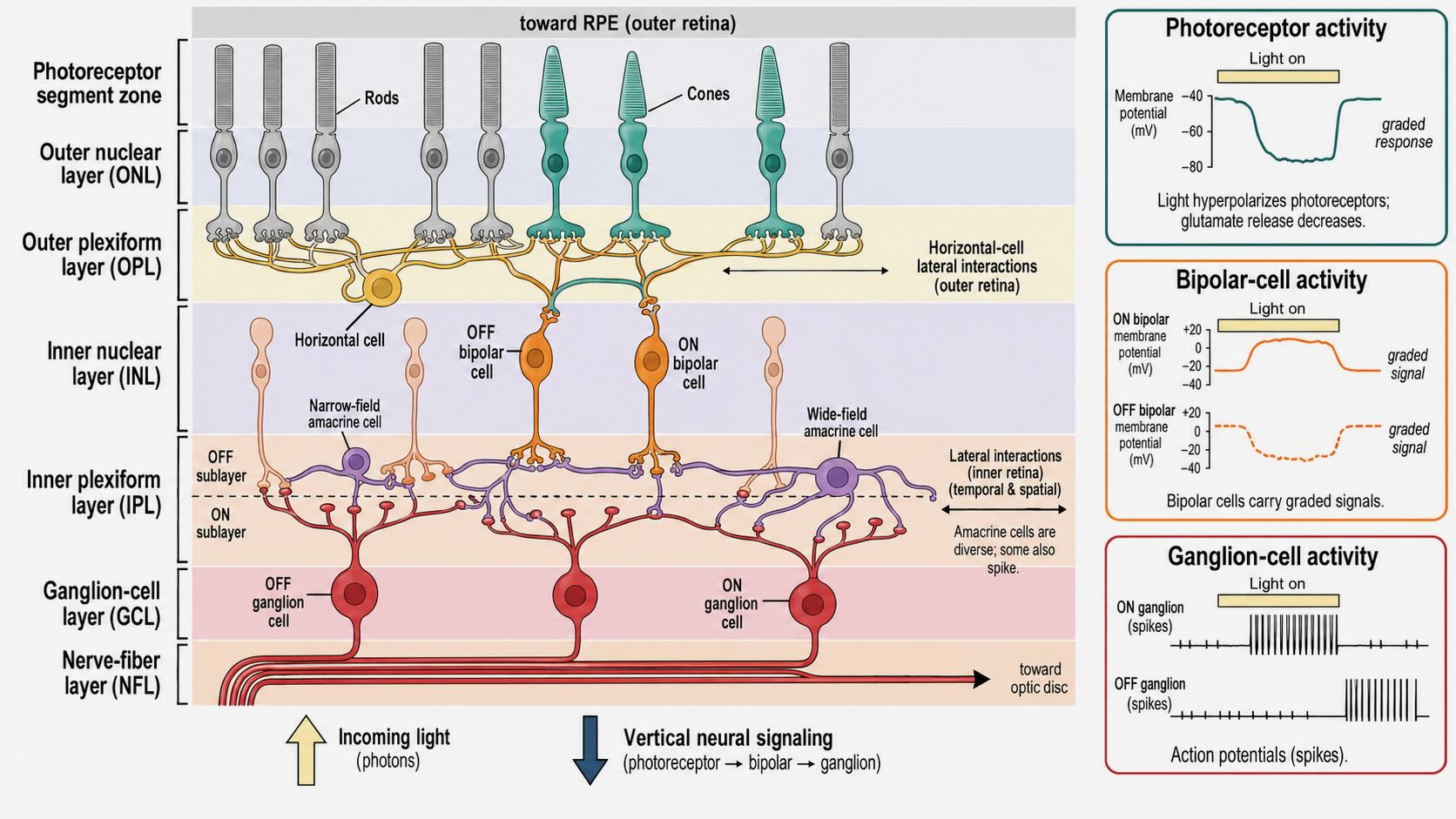
The retina develops from the forebrain and remains connected to it by the optic nerve. Its neurons are arranged in layers, but the simplest route through them contains three principal cell classes:
photoreceptor → bipolar cell → ganglion cell
Rods and cones transduce light into graded changes in membrane voltage. Bipolar cells receive photoreceptor output and carry graded signals toward the inner retina. Ganglion cells integrate bipolar and amacrine input; their axons form the optic nerve and provide the retina’s principal long-range output in the form of action potentials.
The three-cell sequence is only the vertical spine of the circuit. Horizontal cells spread signals laterally in the outer retina, where photoreceptors contact bipolar cells. Amacrine cells provide a much more diverse set of lateral and temporal interactions in the inner retina, where bipolar cells contact ganglion cells. Photoreceptors and most bipolar cells communicate through graded voltage changes and continuous transmitter release. Ganglion cells spike, and some amacrine cells do as well; the retina is therefore not divided perfectly into an analog interior and a digital output [@Masland2012; @SanesMasland2015].
The named cellular layers alternate with synaptic layers. Photoreceptor cell bodies occupy the outer nuclear layer. Their terminals contact horizontal and bipolar cells in the outer plexiform layer. Horizontal-, bipolar-, and many amacrine-cell bodies occupy the inner nuclear layer. Bipolar terminals, amacrine processes, and ganglion dendrites interact in the inner plexiform layer. Ganglion-cell bodies lie in the ganglion-cell layer, and their axons run through the nerve-fiber layer toward the optic disc.
This organization establishes two complementary directions of processing. Vertical pathways carry signals from photoreceptors toward the retinal output. Lateral pathways make the response at one location depend partly on events elsewhere in space and time. The first is necessary to transmit the image. The second changes what the transmitted signal represents.
25.2.1 Rods, cones, and adaptation to light level
The retina must remain useful across illumination that changes by many orders of magnitude. It does not accomplish this with one fixed circuit whose responses simply grow larger as the world becomes brighter. Photoreceptors and downstream neurons continually adjust their gain, and different receptor systems dominate at different light levels.
The average adult human retina contains roughly 92 million rods and 4.6 million cones, with substantial variation among individuals [@CurcioEtAl1990]. Rods are absent from the center of the foveola, increase steeply outside it, and reach their highest density in a broad ring farther from fixation. Cones reach their greatest density in the fovea but are not confined to it; they extend throughout the retina at progressively lower densities.
Rods are specialized for sensitivity. A fully dark-adapted rod can produce a reliable electrical response to one absorbed photon, although conscious detection requires pooling across receptors and must overcome both optical losses and biological noise. Many rods converge through retinal circuitry, increasing the chance that scarce photons will influence an output neuron. The tradeoff is reduced spatial precision. Rod-dominated, or scotopic, vision is therefore highly sensitive but relatively low in acuity and ordinarily lacks color discrimination.
Cones require more light but respond rapidly, adapt over a wide daytime range, and support high spatial resolution and color vision. Cone-dominated, or photopic, vision prevails in daylight. Between the two lies mesopic vision, the mixed regime of dawn, dusk, and dim interiors in which rods and cones both contribute. The transition is not only a change in response amplitude. It changes which receptors and retinal circuits carry the useful signal.
| Lighting regime | Dominant receptor input | Principal advantage | Principal limitation |
|---|---|---|---|
| Scotopic | Rods | Very high sensitivity | Low acuity; little ordinary color vision |
| Mesopic | Rods and cones | Operation across intermediate light | Spatial and chromatic signals change with adaptation |
| Photopic | Cones | High acuity, rapid responses, color | Lower sensitivity than the rod system |
Humans have three cone classes, named for the region of the spectrum to which they are most sensitive: S, M, and L for short-, medium-, and long-wavelength-sensitive cones. The familiar labels “blue,” “green,” and “red” are convenient but misleading. Each cone class has a broad sensitivity curve, and the L and M curves overlap strongly. An L cone does not report “red.” It reports how many photons its photopigment absorbed, given its own spectral sensitivity. Color will emerge only when outputs from different cone classes are compared.
The L- and M-opsin genes arose from a comparatively recent gene duplication in the primate lineage and remain adjacent on the X chromosome. Variation or rearrangement in these genes accounts for the most common inherited forms of red–green color-vision deficiency and helps explain their greater prevalence among people with only one X chromosome [@NeitzNeitz2011; @Jacobs2009].
A small subset of retinal ganglion cells expresses the photopigment melanopsin and is therefore intrinsically photosensitive. These intrinsically photosensitive retinal ganglion cells, or ipRGCs, also receive synaptic input from rods and cones. Their sustained responses to ambient illumination are important for circadian entrainment, the pupillary light reflex, and other effects of light on physiology and behavior [@BersonEtAl2002; @HattarEtAl2002; @DoYau2010].
The older division between an image-forming rod–cone system and a wholly separate “non-image-forming” melanopsin system is too sharp. In primates, some melanopsin ganglion cells project to the lateral geniculate nucleus, receive cone-opponent input, and are positioned to influence conscious vision. Human experiments also indicate a melanopsin contribution to perceived brightness, especially for large, slowly changing fields [@DaceyEtAl2005; @ZeleEtAl2018]. Melanopsin does not provide fine spatial vision, but neither is it irrelevant to seeing.
25.3 Phototransduction: light reduces photoreceptor output
Most sensory receptors depolarize when their preferred stimulus increases. Vertebrate photoreceptors do the opposite. In darkness, a rod or cone is relatively depolarized and releases glutamate continuously. Absorbing light hyperpolarizes the cell and reduces glutamate release. This reversal is the first place where students are often tempted to attach the wrong meaning to a sign. Light is not “inhibitory” in any general sense. It closes an inward current in the photoreceptor; downstream cells then interpret the resulting decrease in glutamate in different ways.
25.3.1 The dark current
A photoreceptor contains an outer segment specialized for capturing photons, an inner segment containing much of the cell’s metabolic machinery, and a synaptic terminal that releases glutamate. In darkness, the concentration of cyclic GMP, or cGMP, is relatively high in the outer segment. cGMP binds to cyclic-nucleotide-gated channels and keeps them open. Sodium and calcium ions therefore enter the outer segment while potassium continues to leave through channels in the inner segment. This circulating ionic flow is the dark current.
The name is easy to misunderstand. Dark current is not a current produced by darkness as a stimulus, and it is not simply sodium moving inward at one point. It is a standing circuit of ionic movement: cations enter through the outer segment, positive charge leaves principally as potassium through the inner segment, and pumps and exchangers continually restore the gradients. The net effect is to hold the photoreceptor at a relatively depolarized membrane potential. Voltage-gated calcium channels at the synaptic terminal remain partly open, and the cell releases glutamate tonically.
Darkness is therefore an active and metabolically expensive state. Photoreceptors must continually maintain ionic gradients and renew outer-segment components. Their oxygen consumption is especially high in darkness and falls when illumination closes part of the dark current [@WangsaWirawanLinsenmeier2003].
25.3.2 The light-activated cascade
When a photon is absorbed, the 11-cis retinal chromophore within an opsin changes configuration. Activated opsin stimulates the G protein transducin, which activates phosphodiesterase 6, or PDE6. PDE6 lowers the concentration of cGMP. With less cGMP available, cyclic-nucleotide-gated channels close, sodium and calcium entry declines, and the continuing potassium efflux drives the membrane potential more negative. The photoreceptor hyperpolarizes. Calcium entry at the synaptic terminal falls, and the rate of glutamate release decreases.
The sequence is worth learning as a causal chain rather than as a list of molecules:
photon → activated opsin → transducin → PDE6 → less cGMP → CNG channels close → hyperpolarization → less glutamate
Recovery mechanisms then restore cGMP, quench activated components of the cascade, and adjust sensitivity to the prevailing background. Rods amplify single-photon events strongly; cones recover more rapidly and remain useful at higher illumination. The molecular details differ in ways that support those functional specializations, but the sign of the response is shared: light closes the outer-segment current and reduces transmitter release [@LambCollinPugh2007; @FainHardieLaughlin2010].
| State of the photoreceptor | Darkness | Light increment |
|---|---|---|
| cGMP in the outer segment | Relatively high | Falls |
| CNG channels | More open | More closed |
| Na(+)/Ca({2+}) entry | Continues | Decreases |
| Membrane potential | Relatively depolarized | Hyperpolarizes |
| Ca(^{2+}) entry at terminal | Greater | Reduced |
| Glutamate release | Tonic and relatively high | Decreases |
25.3.3 Glutamate does not carry one fixed instruction
We introduced glutamate as the principal excitatory transmitter of the adult central nervous system. That is a useful generalization, but it is not a law assigning glutamate one permanent postsynaptic meaning. As stated several times in this textbook, signaling molecules like neurotransmitter bind to receptors. The receptors, their associated ion channels, and the electrical state of the receiving cell determine the effect.
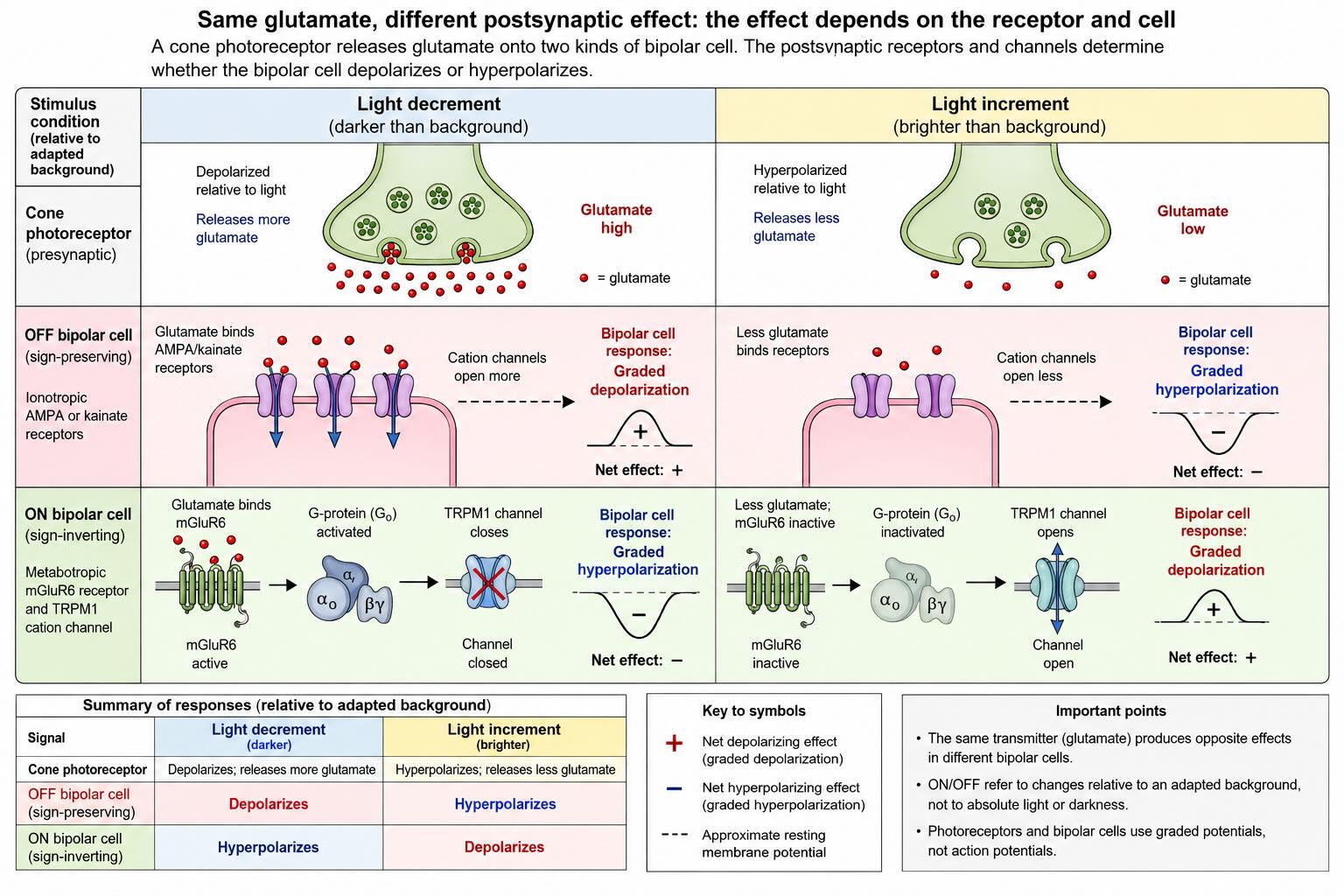
The first retinal synapse makes this principle unusually clear. A cone terminal releases the same glutamate onto two broad classes of bipolar cell, but the cells express different glutamate receptors and respond with opposite signs.
OFF bipolar cells express ionotropic AMPA or kainate receptors. Glutamate opens cation channels and tends to depolarize the cell. The photoreceptor-to-OFF-bipolar synapse is therefore sign-preserving: when the photoreceptor releases more glutamate, the OFF bipolar cell becomes more depolarized; when a light increment reduces glutamate, the OFF bipolar cell hyperpolarizes.
ON bipolar cells express the metabotropic receptor mGluR6. In darkness, glutamate activates mGluR6 and its G-protein cascade, which closes the cation channel TRPM1. The ON bipolar cell is therefore relatively hyperpolarized. A light increment reduces glutamate, mGluR6 signaling falls, TRPM1 channels open, and the ON bipolar cell depolarizes. The synapse is sign-inverting [@MorgansEtAl2009].
The result can be traced in one table:
| Signal | Darkness or a light decrement | Light increment |
|---|---|---|
| Photoreceptor | Depolarizes relative to light; releases more glutamate | Hyperpolarizes; releases less glutamate |
| OFF bipolar cell | Depolarizes | Hyperpolarizes |
| ON bipolar cell | Hyperpolarizes | Depolarizes |
The words ON and OFF refer to changes relative to an adapted background. An ON pathway preferentially reports a local light increment. An OFF pathway preferentially reports a local light decrement. OFF does not mean that the pathway waits for total darkness, and ON does not mean that it reports the absolute presence of light. A dark letter on a white page contains local decrements; a bright star against a dark sky contains local increments. The retina carries both because the two kinds of change are behaviorally and statistically distinct.
Photoreceptors and bipolar cells should be described here as depolarizing or hyperpolarizing, not as firing more or fewer action potentials. Their voltage changes alter graded transmitter release. Spiking becomes the principal output code at the ganglion cells.
Begin with a cone viewing an adapted gray background. The center of its receptive field now becomes brighter.
- Does the cone depolarize or hyperpolarize?
- Does glutamate release rise or fall?
- What happens to an OFF bipolar cell?
- What happens to an ON bipolar cell?
Answer. The cone hyperpolarizes and releases less glutamate. The OFF bipolar cell loses ionotropic glutamatergic drive and hyperpolarizes. The ON bipolar cell loses mGluR6 activation, opens TRPM1 channels, and depolarizes. A light decrement reverses this sequence.
The principal mammalian rod pathway contains an apparent puzzle. Rods contact rod bipolar cells, and rod bipolar cells are ON cells. How, then, can dim vision contain OFF responses?
Rod bipolar cells excite AII amacrine cells. AII cells pass the signal into ON cone pathways through electrical synapses and into OFF cone pathways through inhibitory glycinergic synapses. The sign of that inhibition converts the rod-driven ON signal into an appropriate OFF signal. Additional rod routes—through rod–cone gap junctions and, in some species and conditions, direct contacts with cone bipolar cells—also contribute [@Wassle2004; @Masland2012]. Rod vision therefore borrows and modifies circuitry used by cone pathways rather than traveling through a single dedicated “rod channel” to the brain.
25.4 Spatial comparison: center and surround
The photoreceptor array contains far more information than the optic nerve can transmit independently, and much of that information is redundant. Neighboring receptors usually view neighboring parts of the same surface and therefore receive similar illumination. The retina does not solve this bottleneck by abandoning information about light level. It uses several forms of adaptation to shift its operating range as the background changes, while center–surround circuits emphasize how one region differs from nearby regions.
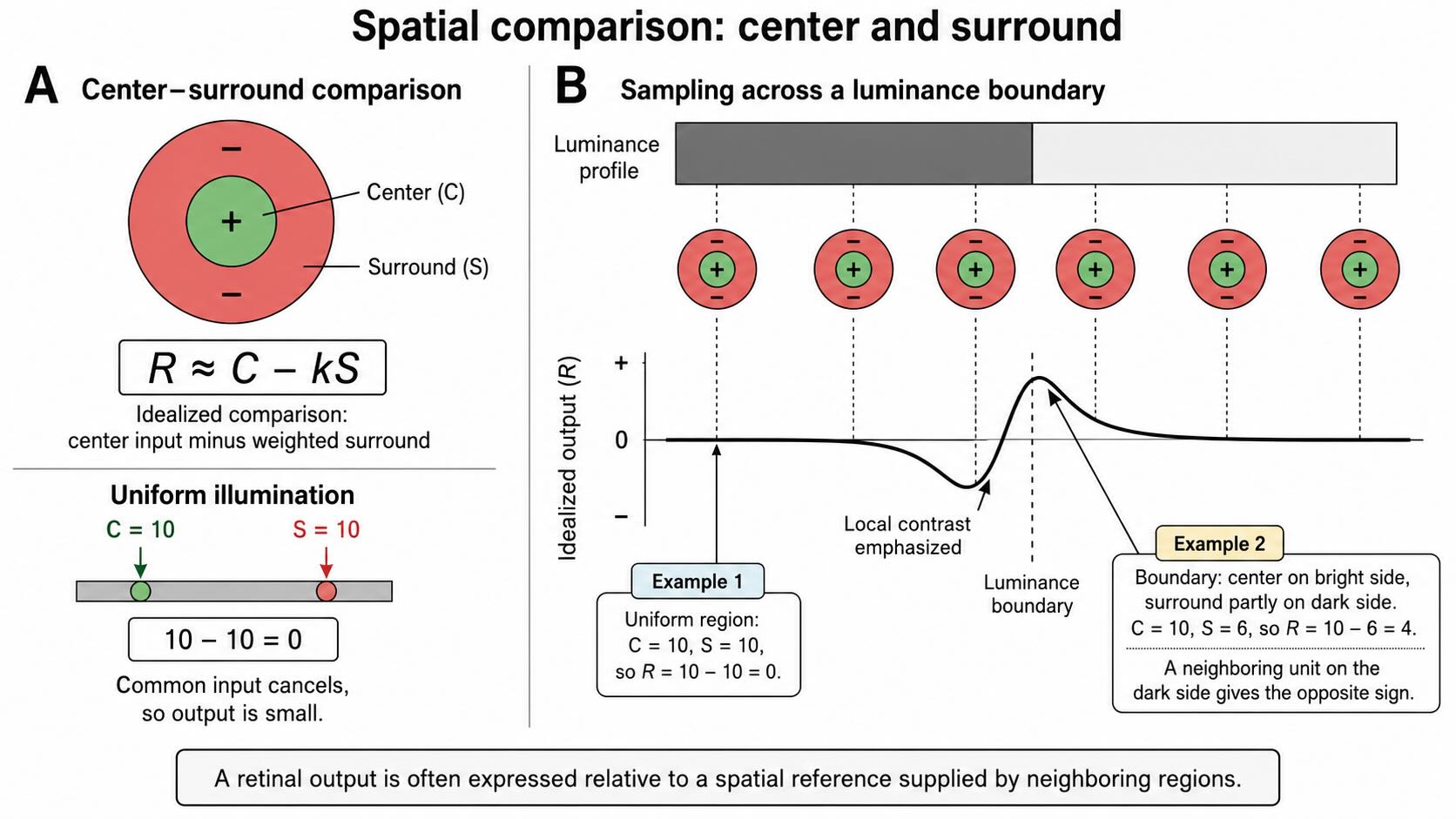
That distinction matters. A ganglion cell does not simply report the number of photons falling on one photoreceptor. Its response often depends on a comparison resembling:
\[ R \approx C - kS \]
Here, (C) is the input from a relatively small central region, (S) is a weighted average over a broader surrounding region, and (k) describes the strength of the surround. The equation is an introductory model, not the literal arithmetic performed by every retinal neuron. Its purpose is to make the comparison visible.
Consider an idealized unit whose center and surround are equally weighted.
25.4.1 Uniform illumination
Suppose the center and surrounding region each receive an input of 10:
[ 10 - 10 = 0 ]
The inputs are large, but they match. In this simplified steady-state case, the output is small because the common component cancels.
25.4.2 A luminance boundary
Now place the center on a brighter region while part of the surround falls on a darker region. Suppose the center input remains 10 but the surround average falls to 6:
[ 10 - 6 = 4 ]
The output is larger because center and surround no longer match. A neighboring unit centered on the darker side of the boundary can produce a response of the opposite sign. An array of such comparisons therefore emphasizes local contrast—spots, boundaries, and spatial changes—while responding less strongly to broad regions that vary together.
This is the computational idea behind lateral inhibition. The phrase can evoke a misleading image in which an excited ganglion cell directly suppresses adjacent ganglion cells. Retinal surrounds are instead assembled through lateral pathways before and within the ganglion-cell circuit. Horizontal cells pool photoreceptor signals and feed effects back to photoreceptor terminals or forward to bipolar dendrites in the outer retina. Amacrine cells influence bipolar terminals and ganglion cells in the inner retina. The relative contribution of these pathways differs across species, ganglion-cell types, adaptation states, and stimulus conditions. In primate parasol cells under photopic conditions, outer-retinal horizontal-cell mechanisms make a major contribution, while inner-retinal circuits can add further surround effects [@VerweijEtAl2003; @McMahonEtAl2004].
The general operation is more important at this stage than assigning every surround to one interneuron:
A retinal output is often expressed relative to a spatial reference supplied by neighboring regions.
25.4.3 Receptive fields make the comparison visible
A neuron’s receptive field is the region of sensory space in which stimulation can change its response. For a photoreceptor, that region is set principally by the light captured by one outer segment. A bipolar or ganglion cell receives converging input, so its receptive field is larger and reflects the organization of the circuit leading to it.
The classical retinal ganglion-cell receptive field contains two antagonistic zones. An ON-center/OFF-surround cell increases its firing when light in the center becomes brighter than the adapted background and decreases its firing when the surround becomes brighter. An OFF-center/ON-surround cell has the opposite organization: a decrement in the center increases firing, whereas a decrement in the surround opposes it.
For an idealized ON-center cell:
- A small light increment restricted to the center strongly increases firing.
- A lighted annulus restricted to the surround suppresses firing.
- A large uniform field stimulates center and surround together, producing a smaller sustained response than a center spot.
- A boundary crossing the receptive field can produce a strong response because center and surround receive different inputs.
The OFF-center cell reverses the preferred contrast. A dark center spot against a lighter background increases its firing; darkening the surround suppresses it.
Two qualifications prevent the model from becoming a new misconception. First, real center and surround components are rarely balanced perfectly. A uniform field can evoke transient responses at onset or offset, and some ganglion-cell types encode more global properties that do not fit the classical model. Second, a center–surround ganglion cell is not an oriented edge detector in the sense later used for neurons in primary visual cortex. It responds well to small spots and other local contrasts. Its circularly organized comparison supplies information from which later circuits can construct selectivity for orientation, motion, and form.
Many ganglion cells maintain a spontaneous firing rate under steady conditions. A light increment or decrement can therefore move firing above or below a baseline. The baseline allows a spike train to represent changes of both signs even though firing rate itself cannot fall below zero. ON and OFF populations provide a further division of labor, ensuring that increments and decrements are each represented by increases in the firing of some neurons rather than only by decreases in another population.
25.4.4 What center–surround coding accomplishes—and what it does not
Center–surround organization makes retinal output sensitive to spatial relationships. It reduces responses to predictable common input, increases sensitivity to local contrast, and helps the circuit use its limited response range under changing conditions. Similar antagonistic organization appears in several sensory systems because comparison with a nearby reference can reveal structure that is difficult to see in absolute measurements.
It does not follow that the retina discards illumination. Photoreceptors adapt to mean light level; ganglion-cell populations retain information about increments, decrements, contrast, temporal change, and in some channels irradiance; and melanopsin cells explicitly report broad changes in ambient light. Nor does a center–surround circuit by itself explain lightness or color constancy. Perceived surface color across shadows and illuminants depends on adaptation and contextual processing distributed from retina through cortex. The retinal surround supplies an important local comparison, not the whole perceptual solution.
Imagine two ON-center ganglion cells. The center and surround of Cell A lie entirely within a uniformly bright wall. The center of Cell B lies on the wall, but much of its surround lies on a dark doorway.
- Both centers receive strong light.
- Which cell should show the larger sustained response?
Answer. Cell B. For Cell A, center and surround rise together and oppose one another. For Cell B, the bright center is compared with a darker surround, so the mismatch is larger. The cell is reporting local contrast, not simply the brightness at its center.
25.5 Color begins with comparison
Light can vary in total intensity and in its distribution across wavelengths. Most natural lights contain mixtures of wavelengths, and the spectrum reaching the eye depends jointly on the illumination and on the wavelengths a surface reflects. The retina does not contain a separate receptor for every possible spectrum. It begins with three broadly tuned cone classes and extracts chromatic information from their relative responses.
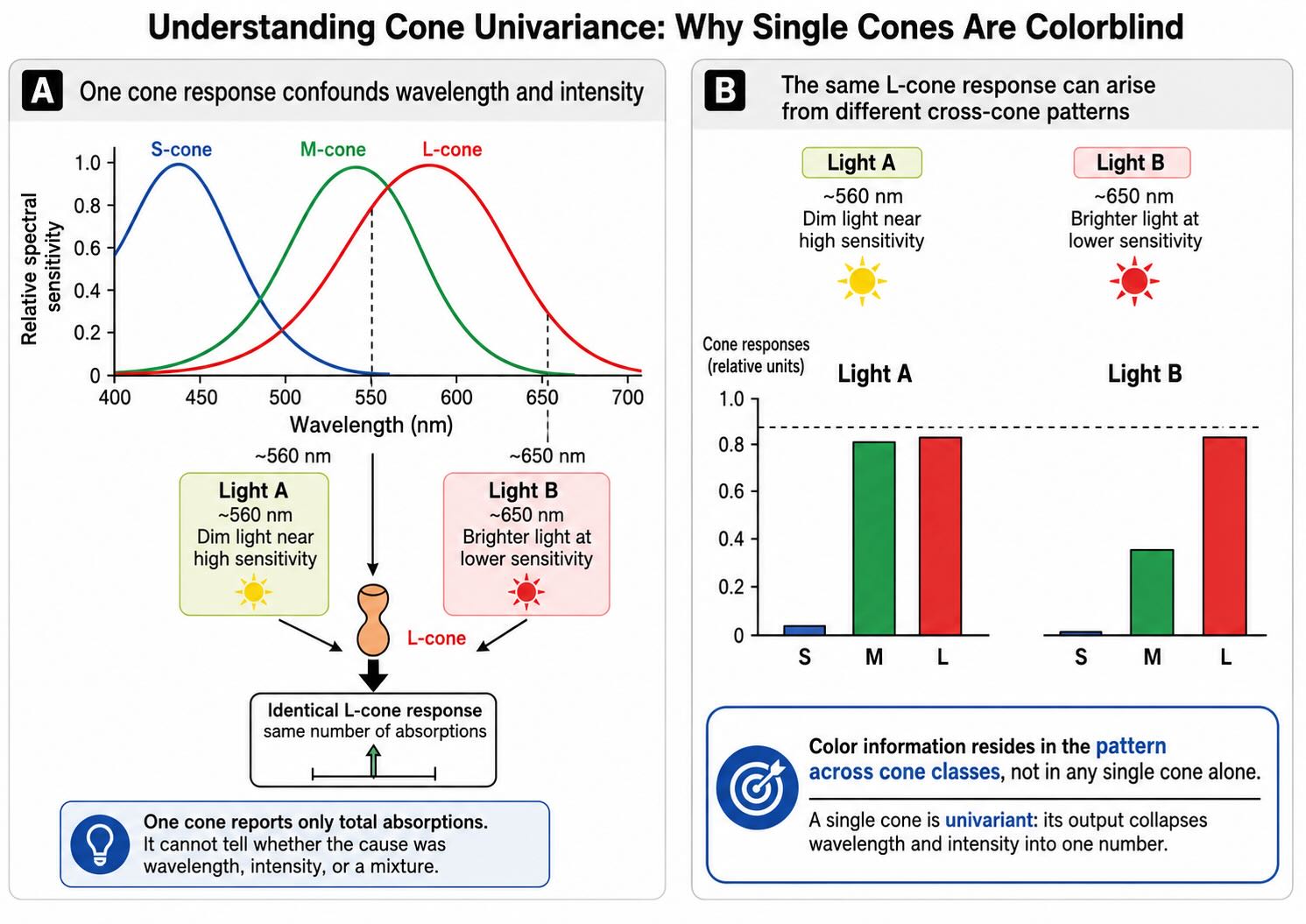
25.5.1 A single cone is univariant
The central difficulty is captured by the principle of univariance. Once a photon has been absorbed, a cone’s electrical response depends on the number of absorptions, not on the identity of the wavelength that produced each one. A photon near the peak of the cone’s sensitivity is more likely to be absorbed than a photon farther from the peak, but an absorbed photon triggers the same transduction machinery.
Suppose an L cone produces a moderate response. That response could have been caused by a modest amount of light at a wavelength to which the L pigment is highly sensitive, a greater amount of light at a less effective wavelength, or a mixture of wavelengths producing the same total number of absorptions. The output contains one number. Wavelength composition and intensity have been collapsed into it.
A single cone is therefore colorblind. This does not mean that the cone fails to respond selectively across the spectrum. Its spectral sensitivity is essential. It means that its response alone cannot distinguish whether a change was caused by wavelength, intensity, or a compensating combination of the two. No later neuron can recover information that was never preserved in the output of that cone.
The familiar “red,” “green,” and “blue” labels obscure this point. An L cone does not announce that red light is present. An M cone does not announce green. An S cone does not announce blue. Each reports absorptions weighted by a broad sensitivity curve. Color information resides in the pattern across cone classes.
25.5.2 The reference is the adapted background
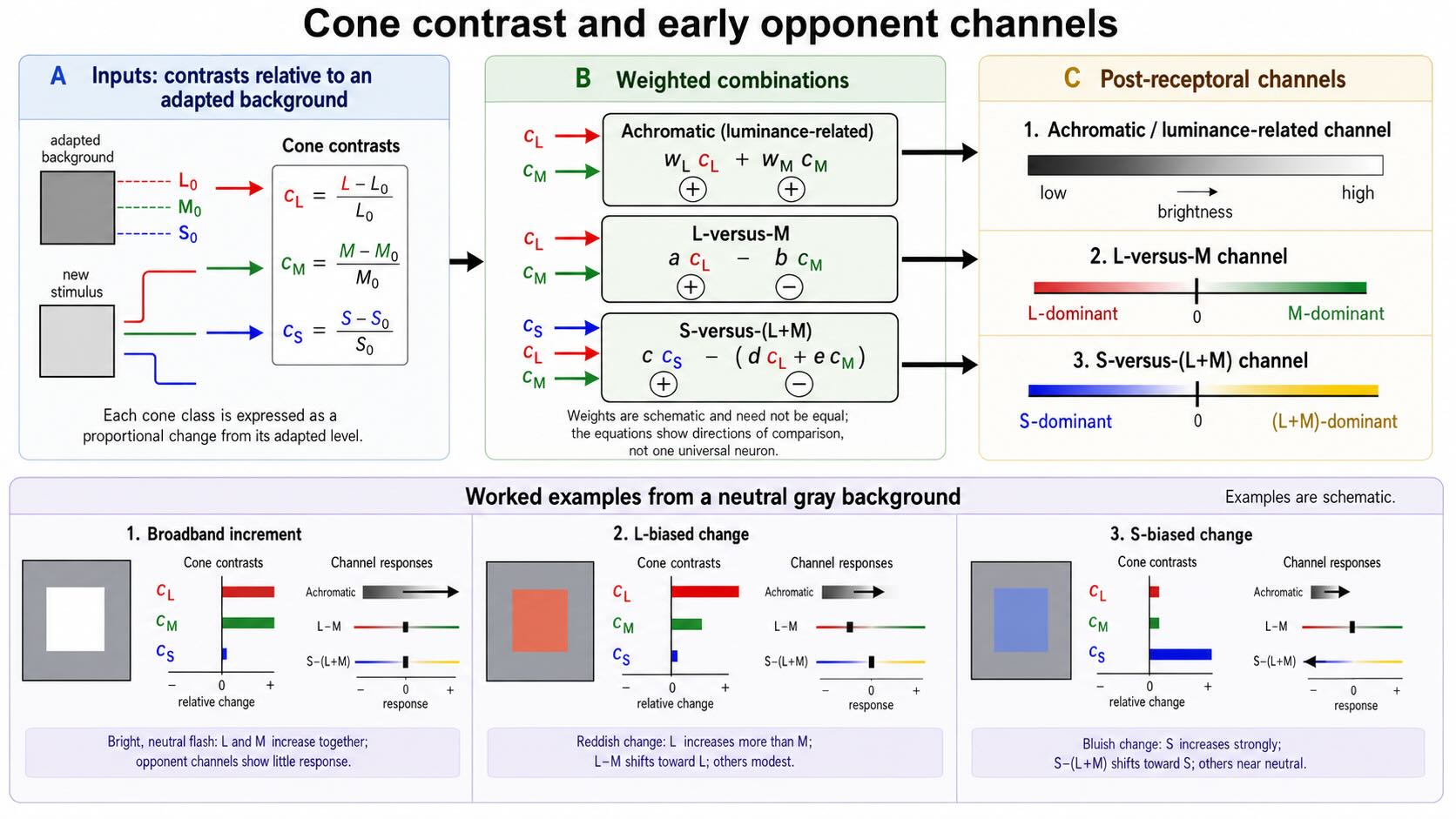
Cone outputs also depend on the recent background. A useful introductory description therefore begins with cone contrast: the proportional change in each cone class relative to its adapted level. For the L cones,
\[ c_L = \frac{L-L_0}{L_0} \]
where (L_0) is the L-cone excitation produced by the background. The corresponding quantities (c_M) and (c_S) describe M- and S-cone contrasts.
This normalization matters. A raw subtraction such as (L-M) does not automatically remove intensity. If an illuminant doubles both raw cone excitations, their numerical difference will usually change as well. Adaptation and gain control express each input relative to a background before, or while, the signals are compared. Early chromatic channels are therefore better understood as comparisons among cone contrasts, not as the subtraction of two unchanging receptor counts.
Three schematic combinations provide a useful scaffold:
\[ \text{achromatic signal} \approx w_Lc_L + w_Mc_M \]
\[ \text{L-versus-M signal} \approx a c_L - b c_M \]
\[ \text{S-versus-(L+M) signal} \approx c c_S - (d c_L + e c_M) \]
The letters \(a\) through \(e\) and \(w_L, w_M\) are weights. They remind us that biological circuits do not necessarily combine cone classes in equal proportions. The equations describe directions of comparison, not universal formulas for every retinal neuron.
The achromatic, or luminance-related, channel adds L- and M-cone contrasts with the same sign. A broadband brightening tends to increase both inputs and therefore increases this signal. The L-versus-M channel compares changes in the two strongly overlapping cone classes. The S-versus-(L+M) channel compares S-cone contrast with a combined L- and M-cone signal.
Consider three simplified changes from a neutral gray background:
- A broadband increment raises L- and M-cone excitation together. It strongly drives the achromatic combination but can leave the L-versus-M comparison relatively small.
- A long-wavelength-biased change raises L-cone contrast more than M-cone contrast. It shifts the L-versus-M signal toward the L-dominant side.
- A short-wavelength-biased change raises S-cone contrast relative to the combined L and M signal. It shifts the S-versus-(L+M) signal toward the S-dominant side.
No channel has identified a wavelength with certainty, and none has read a color directly from one receptor. Each has converted a pattern of receptor changes into a relational signal.
25.5.3 How the opponent signals enter retinal output
In the primate retina, many midget ganglion cells combine L- and M-cone signals antagonistically. Near the fovea, the receptive-field center can inherit input from a single L or M cone through a midget bipolar cell, while the broader surround pools across neighboring cones. This center–surround arrangement can generate an L-versus-M response without requiring a horizontal cell to identify cone type selectively [@DillerEtAl2004; @CrookEtAl2011]. The same spatial circuit that compares center with surround can therefore also produce spectral opponency when the center and surround receive different mixtures of cone input.
A distinct small-bistratified ganglion-cell pathway carries a prominent S-ON/(L+M)-OFF signal. S-cone input reaches one tier of the cell through ON bipolar circuitry, while combined L- and M-cone input reaches an opposing component through other bipolar pathways [@DaceyLee1994]. These examples show that “spatial comparison” and “cone comparison” are not entirely separate pieces of hardware. The same retinal layers and cell classes can contribute to both, although the computations should not be treated as literally identical.
25.5.4 Physiological axes are not color names
The L-versus-M and S-versus-(L+M) channels are often called red–green and blue–yellow channels. The names are useful mnemonics, but they create two risks.
First, the sign of a cone-opponent signal does not equal the amount of a named color in the world. A positive L-versus-M response means that the weighted L-cone contrast exceeds the weighted M-cone contrast for that circuit. It does not mean that an L cone has detected “redness.” The same cone participates in achromatic and chromatic signals, and its contribution depends on the circuit reading it.
Second, the major cone-opponent directions observed in retinal ganglion cells are not identical to the perceptual axes that organize experienced hue. Psychophysical detection thresholds often reveal the cardinal directions L versus M and S versus L+M, whereas judgments of hue require additional combinations. Recent recordings also show that the primate retinal output contains a broader range of cone combinations than the classical two-axis account implies [@GodatEtAl2024]. The retina establishes important chromatic contrasts, but the transformation from those signals to experienced red, green, blue, yellow, and the full space of color continues in the thalamus and cortex.
This distinction also changes how afterimages should be interpreted. After staring at a saturated field, a neutral surface may appear tinged toward a complementary hue. The effect reflects adaptation in cones and postreceptoral opponent pathways. It is evidence that color is encoded relationally, but it is not well described as one “red neuron” becoming tired and revealing a “green neuron.” Several stages adjust their gain and baseline.
| Tempting shorthand | More accurate interpretation |
|---|---|
| “Red cone,” “green cone,” “blue cone” | L-, M-, and S-cone classes with broad, overlapping spectral sensitivities |
| “The cone detects wavelength” | One cone reports absorptions and cannot separate wavelength from intensity |
| “L − M removes brightness” | Opponent circuits compare adapted, weighted cone contrasts; raw subtraction does not automatically remove intensity |
| “Positive L − M means red is present” | The circuit lies on one side of an opponent cone-contrast axis |
| “Blue–yellow is blue minus a yellow receptor” | S-cone contrast is compared with a constructed L+M signal; there is no yellow cone |
| “Retinal opponency is the experience of hue” | Retinal signals constrain color vision, but later transformations contribute to color appearance |
Some mantis shrimps possess as many as 12 spectral receptor classes. That fact once encouraged the claim that their color experience must be vastly richer than ours. Behavioral tests instead found relatively coarse wavelength discrimination, suggesting that their many channels may support rapid categorization rather than the fine comparisons achieved by systems with fewer receptor classes [@ThoenEtAl2014; @Zaidi2014].
The original interpretation—that mantis shrimps largely bypass opponent comparison—has also proved too simple. Behavioral work published in 2025 found evidence of spectral opponency and supports a hybrid system combining receptor-based binning with opponent processing [@WangMarshall2025]. The durable lesson is narrower but stronger: receptor count alone does not determine color performance. Discrimination depends on how receptor outputs are compared, normalized, and used by later circuits.
A gray surface becomes brighter without a large change in spectral composition. Assume that L- and M-cone contrasts rise by similar proportions and that S-cone contrast also changes in the same general direction.
- What happens to an L+M luminance-related channel?
- What happens to an idealized L-versus-M channel?
Answer. The added L+M signal increases. Because the L and M contrasts change together, much of their common change cancels in the opponent comparison, leaving a smaller L-versus-M response. “Smaller” is not necessarily zero: the weights, spectra, and state of adaptation matter.
25.6 Acuity and sensitivity vary across the retina
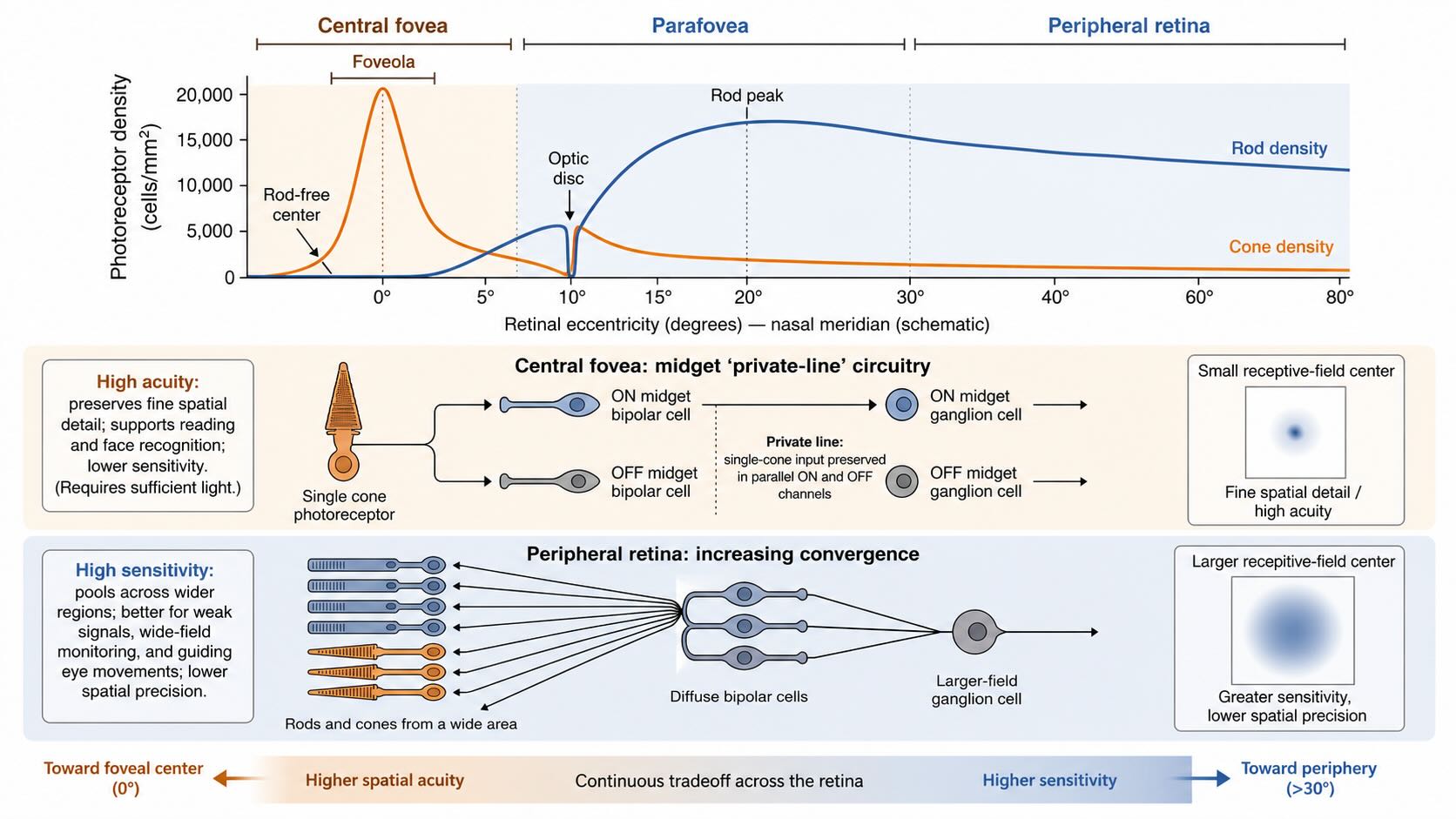
Acuity is often discussed as though it were a property of the eye as a whole. In fact, spatial resolution changes sharply with retinal location. It depends on the optics of the eye, the spacing of photoreceptors, the convergence of their signals onto later neurons, and the size of the resulting receptive fields. The central and peripheral retina make different compromises among resolution, sensitivity, field of view, and the amount of neural tissue devoted to each region.
25.6.1 Foveal circuitry preserves spatial detail
The fovea occupies only a small part of the retinal surface, but it supports the vision used for reading, recognizing a face, threading a needle, or inspecting any object that requires fine detail. Several specializations converge there.
Cone density reaches its maximum in the central fovea, and the inner retinal layers are displaced away from the optical axis. The central fovea contains no rods, and the capillary-free foveal avascular zone reduces obstruction along the path to the cones. These anatomical features improve sampling, but receptor density alone does not determine acuity. Spatial detail would still be lost if many neighboring cones were pooled indiscriminately onto one output neuron.
The central primate retina therefore contains a specialized midget pathway. Near the fovea, one cone can contact an ON midget bipolar cell and an OFF midget bipolar cell, each of which supplies a corresponding midget ganglion cell. The phrase private line refers to this preservation of single-cone input through separate ON and OFF pathways. Serial electron microscopy of human foveal tissue confirms this highly specific cone → midget bipolar → midget ganglion organization [@ZhangEtAl2020]. It is more accurate than the common shorthand “one cone connects to one ganglion cell,” because a single cone can contribute to parallel ON and OFF outputs and because the one-to-one arrangement becomes less common with eccentricity.
Small receptive-field centers allow nearby points in the image to remain distinguishable. The cost is sensitivity. A neuron that samples one cone has fewer opportunities to capture scarce photons than a neuron that pools over a wide region. Fine foveal vision therefore depends on sufficient light and on directing the eyes so that the object of interest falls on this small central specialization.
25.6.2 Peripheral circuitry pools over larger regions
Moving away from the fovea, receptor density declines, rods become abundant, and convergence generally increases. A bipolar or ganglion cell can combine input over a wider retinal area, creating a larger receptive field. Pooling improves the reliability with which weak or noisy signals affect retinal output, but it sacrifices information about which receptor supplied them. The peripheral retina is therefore well suited to surveying a wide field, detecting changes, and guiding an eye movement toward a potentially important event. Once the eyes turn, the image of that event can be sampled by the higher-resolution fovea.
This tradeoff should not be translated into the claim that peripheral experience is simply a blurred, colorless photograph surrounding a sharp central disk. Several distinct limitations are involved. Optical quality, receptor spacing, convergence, cortical magnification, crowding, and attention all change with eccentricity. Cones remain present outside the fovea. With small, unscaled stimuli, chromatic performance declines away from fixation; when stimulus size is increased appropriately, wavelength discrimination remains possible even in the far peripheral field, although foveal performance remains superior [@VanEschEtAl1984]. A static illustration that uniformly blurs everything outside fixation would therefore combine several different phenomena and imply a retinal boundary that does not exist.
Vision instead relies on active sampling. Small eye movements continually shift the retinal image, and larger saccades bring selected locations onto the fovea several times each second. The visual system nevertheless supports the experience of a stable world. How perception remains useful across these discontinuous samples is a question for the later vision chapters; the retinal contribution is to provide complementary high-resolution and high-sensitivity signals from different locations.
25.7 Parallel outputs leave the retina
A single output channel could not preserve all of the distinctions created by the retinal circuit. High spatial resolution favors small receptive fields; sensitivity favors pooling. Sustained responses are useful for representing steady contrast; transient responses are useful for rapid change. Chromatic comparisons require different combinations of cone input than broadband luminance signals. The retina therefore sends many parallel descriptions of the same region of visual space.
Anatomists once divided primate ganglion cells mainly into a few conspicuous classes. Modern anatomical, physiological, and molecular methods reveal many more. The exact taxonomy continues to change, and most cell types are known more completely in mouse than in human retina. The familiar midget, parasol, and small-bistratified populations nevertheless provide a useful introduction because they dominate several major primate pathways [@Masland2012; @SanesMasland2015; @BadenEtAl2016].
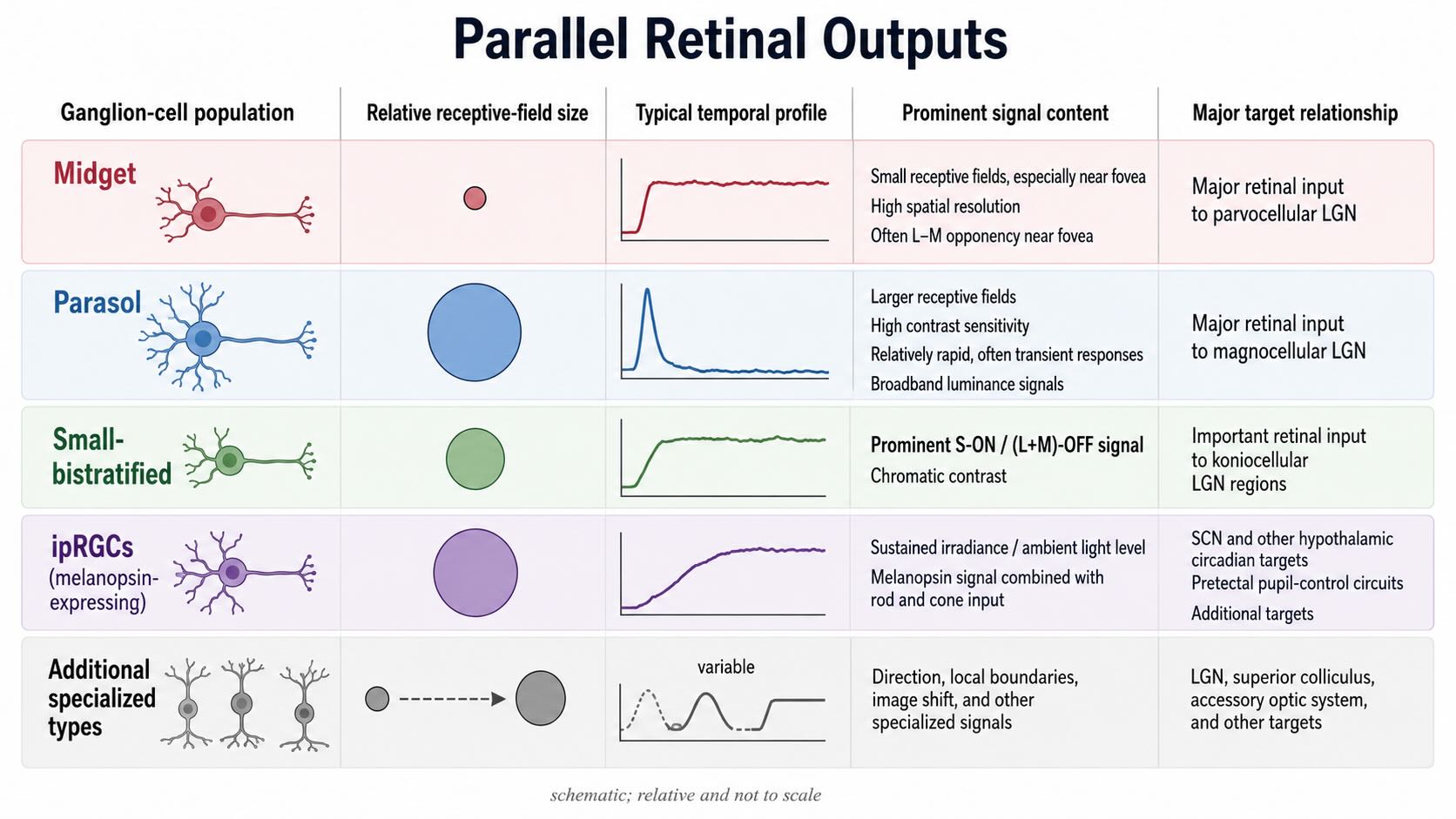
25.7.1 Midget ganglion cells
Midget ganglion cells are especially numerous in primates. Their central receptive fields are small, particularly near the fovea, and their signals support high spatial resolution. Many foveal midget cells also carry L-versus-M cone-opponent information because a single-cone center is compared with a surround containing a different mixture of L- and M-cone signals. At larger eccentricities, convergence increases and midget responses need not remain cleanly chromatic. A cell class should therefore not be defined by one stimulus label alone.
Midget ganglion cells provide the major retinal input to the parvocellular layers of the lateral geniculate nucleus. For that reason, introductory accounts sometimes use midget and parvocellular, or P, as though they named the same neuron. They do not. Midget names a retinal ganglion-cell family; parvocellular names neurons and layers in the LGN. The connection is strong but not an identity.
25.7.2 Parasol ganglion cells
Parasol ganglion cells have larger receptive fields, conduct rapidly, and often respond transiently to changes in luminance contrast. They sacrifice some spatial detail in exchange for greater sensitivity and temporal resolution. Parasol cells provide the major input to the magnocellular LGN layers.
The magnocellular pathway is often called a motion pathway. That shorthand goes too far at the retinal level. A parasol cell responds well to relatively rapid temporal modulation and supplies signals useful for motion analysis, but it does not ordinarily specify the direction and speed of an object in the way later motion-selective neurons can. Motion perception is constructed from spatially and temporally organized inputs across several stages.
25.7.3 Small-bistratified ganglion cells
Small-bistratified ganglion cells receive input in two strata of the inner plexiform layer and carry a prominent S-ON/(L+M)-OFF signal [@DaceyLee1994]. They provide an important retinal input to koniocellular regions of the LGN. Here too, the names should not be collapsed. The koniocellular system is heterogeneous, and small-bistratified cells are one important input rather than a complete definition of the K pathway.
25.7.4 Additional outputs
The three populations above do not exhaust retinal function. Other ganglion cells respond preferentially to particular directions of motion, local boundaries, rapid image shifts, or sustained illumination. Intrinsically photosensitive ganglion cells add signals related to irradiance, circadian time, and pupil control. Some retinal outputs project to the superior colliculus and other midbrain or hypothalamic targets rather than primarily to the LGN. The retina does not prepare one representation and send copies everywhere. Different output populations route different transformations to circuits that control perception, orienting, eye movements, autonomic responses, and biological time.
| Retinal output population | Characteristic contribution | Major projection relationship |
|---|---|---|
| Midget | Small receptive fields; high spatial resolution; often L/M opponency near the fovea | Major input to parvocellular LGN |
| Parasol | Larger fields; high contrast sensitivity; relatively rapid and transient responses | Major input to magnocellular LGN |
| Small bistratified | Prominent S-ON/(L+M)-OFF signal | Important input to koniocellular LGN |
| Melanopsin/ipRGC | Sustained irradiance signal combined with rod and cone input | Hypothalamic, pretectal, LGN, and other targets |
| Additional types | Direction, local contrast, image shift, and other specialized features | LGN, superior colliculus, accessory optic and other targets |
25.7.5 The optic nerve is a bottleneck, not a picture cable
Ganglion-cell axons run across the inner surface of the retina, converge at the optic disc, pass through the lamina cribrosa, and form the optic nerve. By this point, the original photoreceptor responses have been reorganized along several dimensions:
- whether light increased or decreased relative to an adapted background;
- whether the center differed from its spatial surround;
- how L-, M-, and S-cone contrasts differed;
- how rapidly the stimulus changed;
- how broadly the signal was pooled across space; and
- which downstream systems require the information.
The number of ganglion-cell axons is much smaller than the number of photoreceptors, but compression is only part of the story. The optic nerve has not retained every receptor value and then reduced the file size. Retinal circuitry has selected variables, adjusted gains, separated signs, and distributed information among populations with different receptive fields and response dynamics. The result is a transformed representation designed for use by neural circuits, not a miniature image awaiting inspection.
25.8 What the retina has accomplished
The chapter began with an optical image and ended with parallel spike trains. Between those points, the retina performed several linked transformations.
A photon closes channels in a vertebrate photoreceptor, hyperpolarizing the cell and reducing glutamate release. Different glutamate receptors then split that common photoreceptor signal into ON and OFF pathways. Lateral circuits compare each location with a spatial surround, making ganglion-cell output sensitive to local contrast. Comparisons among adapted cone signals create early achromatic and chromatic channels. Unequal convergence across the retinal surface establishes a tradeoff between foveal resolution and peripheral sensitivity. Multiple ganglion-cell populations finally carry complementary products of these operations into the optic nerve.
Spatial surrounds and cone-opponent pathways illustrate a recurring computational principle: a neural signal often becomes more useful when it is expressed relative to an appropriate reference. The references are not the same. One comparison uses neighboring space; another uses other cone classes and an adapted background. Their cells and mechanisms differ. What they share is a move from isolated receptor activity to a code for relationships.
The next chapter follows these signals beyond the eye. Because each optic nerve contains information from one retina rather than from one side of visual space, the partial crossing at the optic chiasm requires careful anatomical bookkeeping. From there, retinal outputs reach the lateral geniculate nucleus, superior colliculus, and other targets before the geniculocortical pathway enters primary visual cortex.
Reasonably well established
- Light activates the opsin–transducin–PDE6 cascade, lowers cGMP, closes CNG channels, hyperpolarizes vertebrate rods and cones, and reduces their glutamate release.
- Ionotropic receptors preserve the sign of the photoreceptor signal in OFF bipolar cells, whereas the mGluR6–TRPM1 cascade inverts it in ON bipolar cells.
- Antagonistic center and surround components make many retinal ganglion cells sensitive to local spatial contrast rather than only to light at one point.
- A single cone obeys the principle of univariance; chromatic information requires comparison across cone classes.
- Primate retinal output contains L-versus-M and S-versus-(L+M) signals as well as luminance-related signals.
- Dense foveal cone sampling and low-convergence midget circuitry support high spatial resolution.
- The optic nerve contains multiple ganglion-cell populations carrying parallel, partly overlapping descriptions of the retinal image.
Established in outline but more complicated than the introductory model
- Horizontal cells, amacrine cells, bipolar cells, and adaptation mechanisms can all contribute to ganglion-cell surrounds; their relative importance depends on cell type and viewing conditions.
- The rod bipolar–AII amacrine circuit is the principal mammalian rod pathway, but secondary and tertiary rod routes also operate.
- Midget, parasol, and small-bistratified ganglion cells provide major inputs to parvocellular, magnocellular, and koniocellular LGN circuitry, but the retinal and thalamic categories are not one-to-one synonyms.
- Retinal cone-opponent signals constrain color vision but do not map directly onto the full organization of experienced hue.
- Melanopsin ganglion cells are central to nonvisual effects of light and can also contribute to conscious visual experience; the extent and conditions of that contribution remain active topics.
- Many less common primate ganglion-cell types have not been characterized as completely as their counterparts in laboratory animals.
- Mantis-shrimp color vision appears to combine receptor-based categorization with spectral opponency; the balance between those strategies is still being resolved.